Redis集群遇到存储倾斜问题,数据分布不均带来的那些烦恼和应对思路

直接提供关于Redis集群存储倾斜问题及其应对思路的内容如下:
根据《Redis开发与运维》一书中的描述,Redis集群在理想状态下,数据应均匀分布在各个节点上,但实际中常出现“存储倾斜”,即大量数据集中到少数几个节点,导致内存使用不均,这带来的烦恼首先是,个别节点内存快速耗尽,触发OOM(内存溢出)或频繁淘汰数据,而其他节点资源闲置,整体集群容量无法有效利用,其次是性能热点,承载过多数据的节点压力过大,请求延迟增加,成为性能瓶颈,影响整个集群的响应速度,最后是运维风险,倾斜节点故障的风险更高,且一旦出问题,数据迁移和恢复的难度与时间都会增加。

数据分布不均的原因多样,一是业务设计导致,例如大量使用顺序增长的键(如incr生成的ID),这些键经哈希计算后可能集中到固定槽位,二是存在“大Key”,即某个Key对应的Value体积巨大(如一个哈希表存放百万字段),它整体存储在一个节点上,占用该节点大量内存,三是哈希标签(Hash Tag)使用不当,虽然本意是将相关键聚合到同一节点以支持事务,但若过度使用或设计不当,反而导致大量数据向个别节点聚集。
应对思路主要从预防和调整两方面入手。键名设计要分散,避免使用单调递增的序列作为键名主体,对于业务上相关的键,可以加入随机前缀或后缀,打散其哈希分布,这是许多Redis实践总结中强调的基础原则。

识别并处理大Key,定期使用redis-cli --bigkeys等工具扫描,发现大Key后,从业务和数据结构上进行优化,将巨型哈希拆分为多个小哈希,或考虑是否可用其他存储方案,阿里云开发者社区的一篇故障分析文章指出,大Key往往是倾斜的“元凶”。
审慎使用哈希标签,仅在确实需要跨键操作(如集群下的事务)时使用,并确保标签的粒度合理,避免将海量数据绑定到同一个标签下。

当倾斜已经发生时,进行数据重平衡,可以通过迁移特定槽位的数据来手动调整,使用redis-cli --cluster reshard命令,将负载过高节点上的部分槽位迁移到负载较低的节点,这个过程需要谨慎操作,避免对线上服务造成影响。
建立监控预警,持续监控每个节点的内存使用量和Key数量,设置差异阈值告警,一旦发现节点间内存使用量差距持续拉大,及时介入分析,腾讯云的技术博客曾分享,他们通过监控节点内存与集群平均值的偏差来提前发现倾斜。
从架构层面考虑,如果业务数据模型本身极易产生倾斜,可能需要评估Redis集群是否完全适合,或者结合使用其他数据分片策略作为补充。
应对Redis集群存储倾斜,重在预防,通过合理的键设计避免热点;同时加强监控,在问题出现早期通过数据迁移等手段进行干预,确保集群的稳定与性能。
本文由革姣丽于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://sbey.haoid.cn/wenda/85645.html
相关文章
-
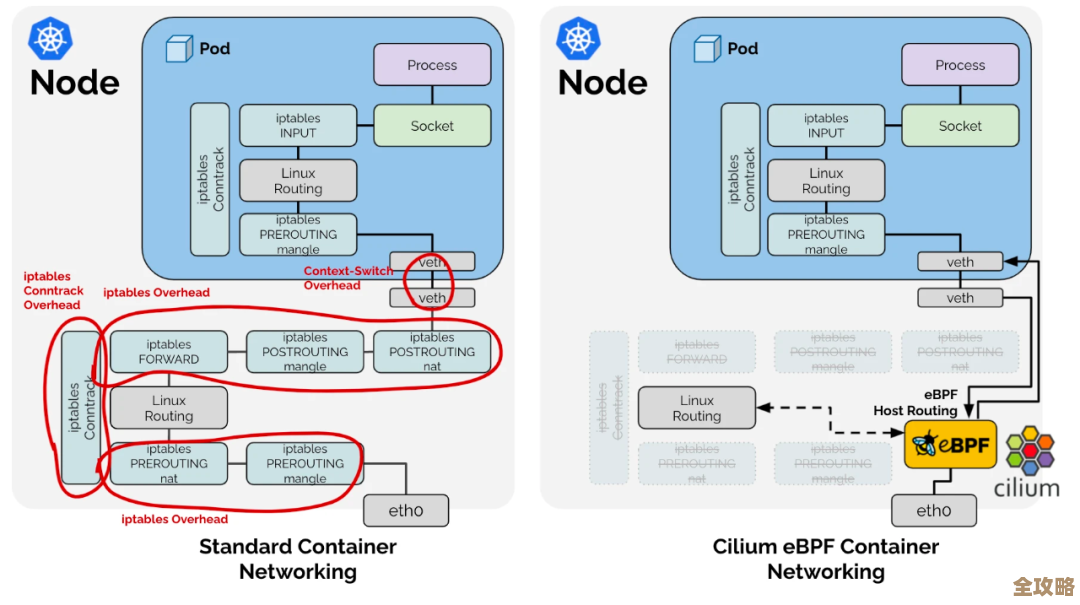
OpenKruise 里那个 CloneSet,专门帮 K8s 工作负载变得更强大和灵活的东西
-
数据库介质出问题了,咱们到底该怎么一步步把数据给恢复回来呢?
-

Oracle和DB2数据库里头那些外部文件格式到底是咋支持的,简单聊聊介绍一下
-
命令之间怎么接着写下一条SQL Server语句,流程咋搞不太清楚
-
ORA-19235错误导致XML处理失败,must-understand扩展不支持引发的报错及远程修复方案分享
-

Redis里怎么快速看集合里的值,分享几个实用小技巧和方法
-
怎么把那些老旧的虚拟机也弄进Istio服务网格里,实际操作咋整呢
-

ORA-29271错误没连上数据库,远程处理故障咋整才好呢